
crf系统,序列标注的强大工具
时间:2024-11-27 来源:网络 人气:
CRF系统:序列标注的强大工具
条件随机场(Conditional Random Field,CRF)是一种广泛应用于序列标注任务的统计模型。它能够有效地处理序列数据中的依赖关系,并在自然语言处理(NLP)领域取得了显著的成果。本文将详细介绍CRF系统的原理、应用以及实现方法。
一、CRF系统概述
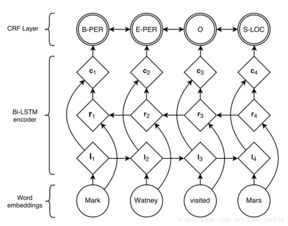
CRF系统是一种基于概率的判别式模型,它通过考虑序列中相邻元素之间的依赖关系来进行标注。与传统的隐马尔可夫模型(HMM)相比,CRF系统不依赖于输出独立性假设,能够更好地捕捉序列中的上下文信息。
二、CRF系统的原理
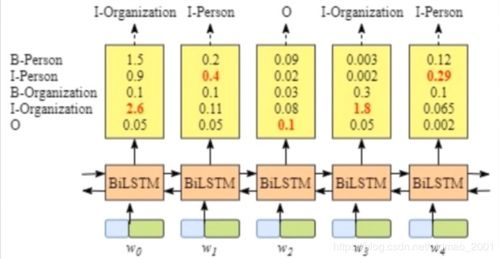
CRF系统通过定义一个条件概率分布来对序列进行标注。具体来说,给定一个观察序列X和标注序列Y,CRF系统计算Y在X条件下的条件概率P(Y|X)。CRF系统的核心思想是,序列中任意位置的状态只依赖于其相邻的状态,以及当前观察到的特征。
三、CRF系统的应用
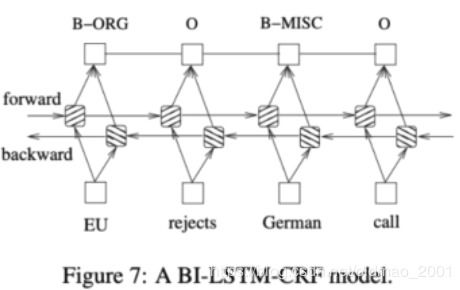
CRF系统在自然语言处理领域有着广泛的应用,以下列举几个典型的应用场景:
命名实体识别(NER):识别文本中的命名实体,如人名、地名、组织名等。
词性标注:对文本中的每个词进行词性标注,如名词、动词、形容词等。
句法分析:分析句子的结构,如主谓宾关系、定语、状语等。
文本分类:根据文本内容对文本进行分类,如情感分析、主题分类等。
四、CRF系统的实现方法
CRF系统的实现方法主要包括以下步骤:
特征工程:根据具体任务,提取文本中的特征,如词频、词性、邻接词等。
构建CRF模型:根据特征和标注数据,构建CRF模型,包括状态空间、转移概率矩阵和观察概率矩阵。
训练模型:使用标注数据对CRF模型进行训练,得到模型参数。
预测标注:使用训练好的CRF模型对新的文本进行标注。
五、CRF系统的优势与局限性
CRF系统具有以下优势:
能够有效地捕捉序列中的依赖关系。
不依赖于输出独立性假设,能够更好地处理序列数据。
模型参数易于解释。
CRF系统也存在一些局限性:
特征工程工作量较大,需要根据具体任务进行调整。
模型参数较多,训练过程可能较慢。
对于长序列数据,模型性能可能下降。
CRF系统是一种强大的序列标注工具,在自然语言处理领域有着广泛的应用。通过本文的介绍,相信读者对CRF系统的原理、应用和实现方法有了更深入的了解。在实际应用中,可以根据具体任务的需求,选择合适的CRF模型和参数,以提高标注的准确性。
教程资讯
教程资讯排行
- 1 安卓系统清理后突然卡顿,系统清理后安卓手机卡顿?揭秘解决之道!
- 2 安卓系统车机密码是多少,7890、123456等密码详解
- 3 vivo安卓系统更换鸿蒙系统,兼容性挑战与注意事项
- 4 希沃白板安卓系统打不开,希沃白板安卓系统无法打开问题解析
- 5 dell进不了bios系统,Dell电脑无法进入BIOS系统的常见原因及解决方法
- 6 x9手机是安卓什么系统,搭载Funtouch OS3.0的安卓体验
- 7 安卓系统优学派打不开,安卓系统下优学派无法打开的解决攻略
- 8 安卓车机怎么查系统内存,安卓车机系统内存检测与优化指南
- 9 Suica安卓系统,便捷交通支付新体验
- 10 12pm哪个系统最好,苹果12哪个版本的系统更省电更稳定





![游戏 [][][] 创意齿轮](/uploads/allimg/20251218/9-25121R03143202.jpg)



